
{kind=link}
നിർമിത ബുദ്ധി പരിശീലനം ലഭിച്ച ചാറ്റ്ജിപിടി (ChatGPT) എന്ന ഒരു ചാറ്റ് ബോട്ട്, ആശയങ്ങളെ ചിത്രങ്ങളാക്കി മാറ്റുന്ന എഞ്ചിനുകളായ ഡീപ്എഐ (DeepAI), മിഡ്ജേണി (Midjourney), ഡാൾ-ഇ (DALL-E), അതിശയകരമായ സെൽഫി ചിത്രങ്ങൾ സൃഷ്ടിക്കുന്ന ലെൻസ (Lensa) പോലുള്ള ആപ്പുകൾ, എന്നിവയെല്ലാം അടുത്ത കാലത്തായി വലിയ വാർത്ത പ്രാധാന്യം നേടിയിട്ടുണ്ടു്. ഡീപ് ലേണിംഗ് (Deep Learning) എന്ന മെഷീൻ ലേണിങ് സാങ്കേതികവിദ്യ ഉപയോഗിച്ചാണു് ഇവയെല്ലാം പ്രവർത്തിക്കുന്നതു്. സ്വാഭാവിക ഭാഷയിൽ ചോദ്യങ്ങൾ ചോദിക്കാൻ നമ്മളെ അനുവദിക്കുന്ന ഒരു സംഭാഷണ ഇന്റർഫേസ് നൽകുന്ന ഒരു നിർമിത ബുദ്ധി ഉപകരണമാണു് ചാറ്റ്ജിപിടി (ChatGPT). ജനറേറ്റീവ് പ്രീ-ട്രെയിൻഡ് ട്രാൻസ്ഫോർമർ (GPT) എന്ന ഒരു ഭാഷാ മാതൃക ഉപയോഗിച്ചിട്ടുള്ള ചാറ്റ് ഇന്റർഫേസ് ആണു് ചാറ്റ്ജിപിടി. സാങ്കേതികവിദ്യ പരിജ്ഞാനം ഇല്ലാത്തവർക്കു് പോലും ഉപയോഗിക്കാവുന്ന രീതിയിലാണു് ഇതു് ക്രമീകരിച്ചിരിക്കുന്നതു്. 2022 നവംബറിൽ അവതരിപ്പിച്ച ഇതു് 5 ദിവസത്തിനു് ശേഷം 1 ദശലക്ഷം ഉപയോക്താക്കളിൽ എത്തുകയുണ്ടായി. അലക് റാഡ്ഫോർഡും സഹപ്രവർത്തകരും എഴുതി, 2018 ജൂൺ 11-നു് പ്രസിദ്ധീകരിച്ച സ്വാഭാവിക ഭാഷാ മോഡലിനെക്കുറിച്ചുള്ള ഒരു പ്രബന്ധം ഒരു ഭാഷാ മോഡലിനു് (language model) എങ്ങിനെ സാമാന്യ വിജ്ഞാനം നേടാൻ കഴിയുമെന്നു് വെളിപ്പെടുത്തി. ഒരു വാചകത്തിലെ വാക്കുകൾ എങ്ങിനെയാണു് പരസ്പരം ബന്ധപ്പെട്ടിരിക്കുന്നതെന്നു് മഷീൻ ലേണിംഗ് ഉപയോഗിച്ചുള്ള പരിശീലനത്തിലൂടെ മനസ്സിലാക്കാൻ സാധിക്കുമെന്നു് ഈ പ്രബന്ധം വിശദീകരിക്കുന്നു. മേൽനോട്ടമില്ലാതെ (unsupervised) പരിശീലിപ്പിക്കുന്ന മഷീൻ ലേണിംഗ് ഭാഷാ മാതൃകയാണു് ഇതിനായി ഉപയോഗിക്കുന്നതു്. ഈ പ്രബന്ധത്തിന്റെ ചുവടു് പിടിച്ചാണു് ഓപ്പൺഎഐ ലബോറട്ടറി വിവിധ ജിപിടി (GPT) മാതൃകകൾ നിർമ്മിച്ചിരിക്കുന്നതു്. ലാഭേച്ഛയില്ലാതെ പ്രവർത്തിക്കുന്ന ഓപ്പൺഎഐയുടെ (OpenAI) ഗവേഷണ ലബോറട്ടറിയാണു് ഇതിന്റെ പിന്നിൽ. ജിപിടി മാതൃകകളുടെ പ്രവർത്തനം എങ്ങിനെയെന്നു് നമുക്കൊന്നു് പരിശോധിക്കാം.
പരസ്പരം ആശയവിനിമയം നടത്താനുള്ള കഴിവു് മനുഷ്യ കുലത്തിന്റെ പുരോഗതിയിൽ ചെറിയ പങ്കല്ല വഹിച്ചിരിക്കുന്നതു്. മറ്റു് പല ജീവിവർഗങ്ങൾക്കും ഇത്തരം കഴിവു് ഉണ്ടെങ്കിൽ തന്നെ അവ വളരെ പരിമിതമാണു്. ഭൂമുഖത്തു് ആകമാനം ഏകദേശം ഏഴായിരത്തിൽ പരം ഭാഷകൾ ഉണ്ടു് എന്നാണു് കരുതപ്പെടുന്നതു്. ഒരു കുട്ടി ജനിക്കുമ്പോൾ ഭാഷ ഉപയോഗിക്കുന്നതിൽ അവന്റെ പരിശീലനം ആരംഭിക്കുന്നു. തുടർന്നങ്ങോട്ടു് എഴുതുന്നതിനും, വായിക്കുന്നതിനും, കല, സാഹിത്യം, സംസ്കാരം എന്നിവ മനസ്സിലാക്കുന്നതിനും, പ്രയോഗത്തിൽ വരുത്തുന്നതിനും ഭാഷാ സ്വാധീനം വലിയ പങ്കു് വഹിക്കുന്നുണ്ടു്.
നിർമിത ബുദ്ധി (ആർട്ടിഫിഷ്യൽ ഇൻറലിജൻസ്) ഗവേഷണങ്ങൾ തുടങ്ങിയ കാലം മുതലുള്ള ശ്രമമാണു് കമ്പ്യൂട്ടറുകൾക്കു് മനുഷ്യരെ പോലെയുള്ള ഭാഷാ സ്വാധീനം നൽകാൻ സാധിക്കുമോ എന്നതു്. ഇതിനായി, വിവിധതരം ഭാഷ മാതൃകകളെപ്പറ്റി പഠിക്കുന്ന നാച്ചുറൽ ലാംഗ്വേജ് പ്രോസസിംഗ് (NLP) എന്ന ഒരു ഉപശാഖ തന്നെ ഈ വിഷയത്തിൽ ഉരുത്തിരിഞ്ഞു വന്നിട്ടുണ്ടു്. ഒരു മനുഷ്യ ഭാഷയെ കമ്പ്യൂട്ടർ മോഡലുകൾ ആക്കി മാറ്റുക എന്നതു് വളരെ സങ്കീർണമായ ഒരു പ്രശ്നമാണു്. നമ്മൾ പറയുന്ന ഓരോ വാക്കും അതിനു് മുൻപുള്ളതും പിന്നീടു് വരുന്നതുമായ വാക്കുകളോടു് ചേർത്തുവച്ചാണു് ഒരു ആശയമായി നാം ആവിഷ്കരിക്കുന്നതു്. ഉദാഹരണത്തിനു് ഒരാൾ “ഞാൻ” എന്നു് പറഞ്ഞാൽ അതിനു പിന്നാലെ അയാൾ ആ സമയത്തു് ചെയ്യാൻ ഉദ്ദേശിക്കുന്നതോ, ചെയ്തു കഴിഞ്ഞതോ ആയ ഒരു പ്രവർത്തിയെ പറ്റിയാകാം പരാമർശിക്കാൻ പോകുന്നതു്.
സന്ദർഭത്തിനനുസരിച്ചു് വരുന്ന വാക്കുകൾ കൃത്യമായി ഉപയോഗിക്കുന്നതിനു് സഹായിക്കുന്ന ഒരു ഭാഷാ മാതൃക നമ്മുടെ തലച്ചോറിനുള്ളിൽ പരിശീലിപ്പിച്ചു് വെച്ചിട്ടുണ്ടു്. തലച്ചോറിനുള്ളിൽ ലഭ്യമായ വലിയ ഒരു പദസഞ്ചയത്തിൽ നിന്നും ഏറ്റവും ഉചിതമായ ഒരു വാക്കായിരിക്കും ഒരാൾ പറയുക. ഓരോ തവണയും നമ്മൾ സംസാരിക്കുമ്പോൾ ആ മോഡലിനുള്ളിൽ നിന്നു് ഉചിതമായ പദങ്ങൾ സന്ദർഭത്തിനനുസരിച്ചു് തിരഞ്ഞെടുത്തു് ഉപയോഗിക്കാനുള്ള കഴിവാണു് ഒരാളുടെ ഭാഷാ സ്വാധീനം. കവികൾക്കും എഴുത്തുകാർക്കും പ്രാസംഗികർക്കും ഒക്കെ ഈ കഴിവു് കൂടുതലായിരിക്കും.
ഭാഷാ മാതൃകകൾ എന്നാൽ മുന്നേ നൽകിയ പദങ്ങളുടെ ക്രമത്തിൽ നിന്നു് അടുത്ത വാക്കു് പ്രവചിക്കാൻ കഴിയുന്ന പ്രോബബിലിസ്റ്റിക് മോഡലുകളാണു്. മെഷീൻ വിവർത്തനം, ചോദ്യോത്തരം, ആശയങ്ങളെ സംഗ്രഹിക്കുക, ചിത്രങ്ങളുടെ അടിക്കുറിപ്പു് തയ്യാറാക്കുക പോലുള്ള നിരവധി കാര്യങ്ങൾ അനായാസം ചെയ്യാൻ ഇവയ്ക്കു് കഴിയും. കമ്പ്യൂട്ടറുകളെ കൊണ്ടു് ഇത്തരം മോഡലുകളെ ഉണ്ടാക്കുന്നതിനു് വ്യത്യസ്ത നിർമിത ബുദ്ധി സങ്കേതങ്ങൾ ഉപയോഗിക്കാം. മനുഷ്യന്റെ ഭാഷയെ വിശകലനം ചെയ്തു് ആശയങ്ങളെ മാത്രം കണ്ടെത്തി പലതരത്തിലുള്ള പ്രോസസിങ്ങുകളും നടത്താൻ കഴിവുള്ള സാങ്കേതികവിദ്യകൾ ഗവേഷകർ ആവിഷ്കരിച്ചിട്ടുണ്ടു്. ഇതിന്റെ സഹായത്താലാണു് പലപ്പോഴും നമുക്കു് തർജ്ജമ, ടെക്സ്റ്റ്-ടു-സ്പീച്ച്, സ്പീച്-ടു-ടെക്സ്റ്റ് തുടങ്ങിയ സൗകര്യങ്ങൾ മൊബൈൽ ഫോണിലും മറ്റും ലഭിക്കുന്നതു്. ഇത്തരം ഒരു ഭാഷാ മാതൃകയാണു് ജിപിടി അഥവാ ജെനറേറ്റിവ് പ്രീട്രെയിൻഡ് ട്രാൻസ്ഫോമർ (Generative Pre-trained Transformer). നമുക്കു് ഇതിലെ ഓരോ ഘടകവും എന്താണെന്നു് നോക്കാം:
വസ്തുക്കളെ തരംതിരിക്കാൻ സ്റ്റാറ്റിസ്റ്റിക്സിൽ പൊതുവെ രണ്ടു് തരം മോഡലുകൾ ഉപയോഗിക്കുന്നു. ഡിസ്ക്രിമിനേറ്റീവ് (discriminative) എന്നും, ജനറേറ്റീവ് (generative) എന്നും വിളിക്കുന്ന ഈ മോഡലുകളിൽ ആദ്യത്തേതു് ടാർഗെറ്റ് വേരിയബിളുകളുടെ സോപാധിക പ്രോബബിലിറ്റിയും (conditional probability), ജനറേറ്റീവ് മോഡലുകൾ സംയുക്ത പ്രോബബിലിറ്റിയും (joint probability) കണക്കാക്കുന്നു. ജനറേറ്റീവ് മോഡലുകൾക്കു് നിലവിലുള്ള ഡാറ്റയ്ക്കു് സമാനമായി പുതിയ ഡാറ്റ സൃഷ്ടിക്കാൻ കഴിയും.
- ഡിസ്ക്രിമിനേറ്റീവ് മോഡൽ:
- കാറുകളുടെയും ബസുകളുടെയും ചിത്രങ്ങൾ കണ്ടാൽ തിരിച്ചറിയാൻ കഴിവുള്ള ഒരു നിർമ്മിത ബുദ്ധി സംവിധനം ഉണ്ടാക്കണം എന്നിരിക്കട്ടെ. കാറുകളുടെയും ബസ്സുകളുടെയും ആയിരക്കണക്കിനു് ചിത്രങ്ങൾ കാണിച്ചു് ഇതിനുള്ള മോഡലിനെ പരിശീലിപ്പിക്കുന്നതു് വഴി ഇതുവരെ കണ്ടിട്ടില്ലാത്ത പുതിയ ഒരു കാറിന്റെയൊ ബസിന്റെ ചിത്രം കണ്ടാൽ കമ്പ്യൂട്ടറിനവയെ കൃത്യമായി തിരിച്ചറിയാൻ കഴിയും. എന്നാൽ ഈ മോഡലിനെ ഒരു പൂച്ചയുടെ ചിത്രമാണു് കാണിക്കുന്നതു് എങ്കിൽ ഈ സംവിധാനം അതിനെയും ഒരു കാറോ ബസോ ആയി മാത്രമേ തിരിച്ചറിയുകയുള്ളൂ. നമ്മൾ കാണിക്കുന്ന ചിത്രത്തിനു് ഏറ്റവും കൂടുതൽ സാമ്യമുള്ളതു് കാറിനോടാണോ ബസിനോടാണോ എന്നാണു് ഈ ഡിസ്ക്രിമിനേറ്റീവ് മോഡൽ പരിശോധിക്കുന്നതു് കാരണം ഈ മോഡൽ കാറിനെയും ബസ്സിനെയും മാത്രം തിരിച്ചറിയാനുള്ള പരിശീലനമാണു് നേടിയിട്ടുള്ളതു്. അതു് ഇതുവരെ പൂച്ചയെ ചിത്രങ്ങൾ തിരിച്ചറിയാനുള്ള പരിശീലനം നേടിയിട്ടില്ല. നമ്മുടെ തലച്ചോറ് ഒരു ഒന്നാന്തരം ഡിസ്ക്രിമിനെറ്റിവ് മോഡലാണു്. ഒറ്റ തവണ കണ്ടാൽ തന്നെ നമുക്കു് പിന്നീടു് വസ്തുക്കളെ തിരിച്ചറിയാനാകും. ഇക്കാര്യത്തിൽ ഇപ്പോഴത്തെ നിർമ്മിത ബുദ്ധി സംവിധാനങ്ങൾ ഒന്നും തന്നെ തലച്ചോറിനു് അടുത്തെങ്ങും എത്തിയിട്ടില്ല. ഇത്തരം മോഡലുകളെ നിർമിക്കാൻ നൂറൽ ശൃംഖലകൾ (neural network) പോലെയുള്ള നിരവധി സങ്കേതങ്ങൾ ആവശ്യമാണു്.
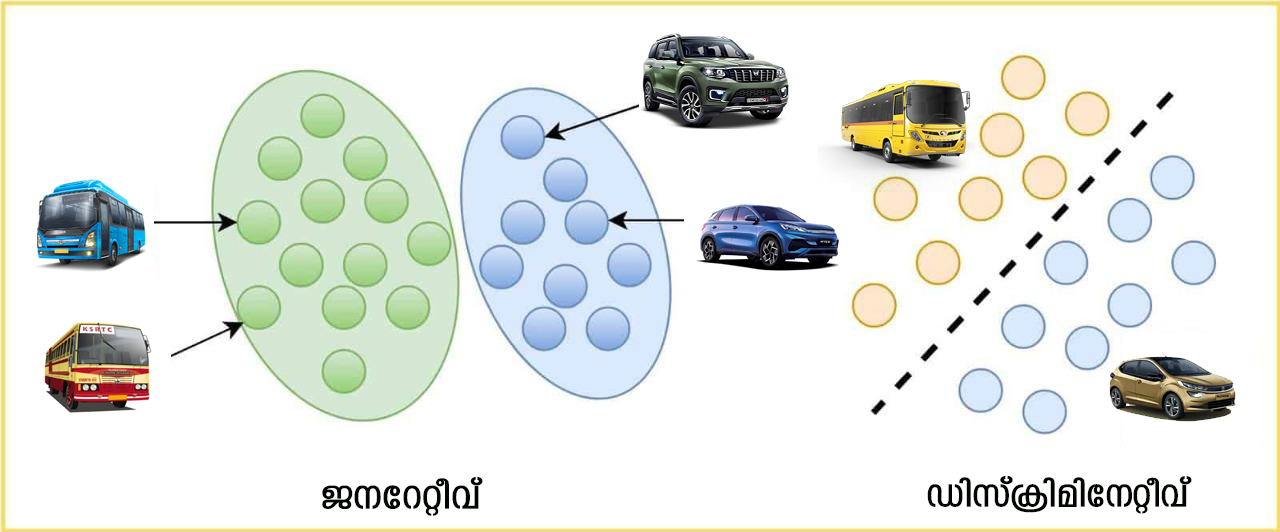
- ജനറേറ്റീവ് മോഡലുകൾ:
- കൃത്രിമമായി മുഖങ്ങളുടെ ചിത്രങ്ങൾ ഉണ്ടാക്കുന്ന ഒരു മോഡൽ നമുക്കു് ആവശ്യമുണ്ടെന്നു് ഇരിക്കട്ടെ. (ഇത്തരം ചില വെബ്സൈറ്റുകൾ ഇപ്പോൾ ലഭ്യമാണു് https://thispersondoesnotexist.com/). മുഖങ്ങളുടെ കൃത്രിമവും, യഥാർത്ഥവുമായ ചിത്രങ്ങൾ ഒരു കൂട്ടം റാൻഡം വേരിയബിളുകളുടെ ഒരു പ്രത്യേക കോമ്പിനേഷനാണു്. ഓരോ മുഖത്തിന്റെയും സവിശേഷമായ പ്രത്യേകതകൾ ഇത്തരത്തിലുള്ള റാൻഡം വേരിയബിൾകളുടെ വ്യതിയാനങ്ങൾക്കു് അനുസരിച്ചാണു് ഉണ്ടാകുന്നതു്. ഈ വേരിയബിൾ എല്ലാം കൂടി മുഖത്തിന്റെ ആകൃതിയിൽ ചേർന്നു വരുന്നതിനു് ഒരു പ്രോബബിലിറ്റി ഉണ്ടു്. ഇങ്ങനെ മുഖത്തിന്റെ ആകൃതിയിൽ ഇവയെല്ലാം കൂടി ചേർന്നു് വരുന്നതിനു വേണ്ടിയുള്ള ജോയിന്റ് പ്രോബബിലിറ്റി ഡിസ്ട്രിബ്യൂഷൻ എസ്റ്റിമേറ്റ് ചെയ്യുകയാണു് എങ്കിൽ നമുക്കു് കൃത്രിമമായി മുഖങ്ങളുടെ ചിത്രങ്ങൾ ഉണ്ടാക്കിയെടുക്കാനാകും. ഇത്തരം പ്രോബബിലിറ്റി ഡിസ്ട്രിബ്യൂഷനിലെ ഓരോ ബിന്ദുവും ഒരു പുതിയ മുഖമായി മാപ്പ് ചെയ്യാനാകും. ഇത്തരത്തിൽ പ്രോബബിലിറ്റി ഡിസ്ട്രിബ്യൂഷൻ കണ്ടെത്തി അതിൽ നിന്നു് ഒരു പോയിന്റ് തെരഞ്ഞെടുത്താൽ ആ ബിന്ദുവിൽ എത്തിച്ചേരാൻ ഉപയോഗിച്ച റാൻഡം വേരിയബിളുകളുടെ പ്രോബബിലിറ്റിയുടെ കോമ്പിനേഷനിൽ നിന്നു് ഒരു മുഖത്തിന്റെ ചിത്രം നിർമ്മിക്കാം. നമുക്കു് ലഭ്യമായ ഡേറ്റ ഉപയോഗിച്ചു് ഇത്തരത്തിലുള്ള പ്രോബബിലിറ്റി ഡിസ്ട്രിബ്യൂഷനുകളെ എസ്റ്റിമേറ്റ് ചെയ്യുക എന്നതാണു് ജനറേറ്റീവ് മോഡലുകൾ ചെയ്യുന്നതു്. ഇത്തരത്തിൽ ഡിസ്ട്രിബ്യൂഷനുകൾ എസ്റ്റിമേറ്റ് ചെയ്യാൻ അതീവ സങ്കീർണമായ മോഡലുകൾ ഉണ്ടാക്കി ലക്ഷക്കണക്കിനു് ചിത്രങ്ങൾ ഉപയോഗിച്ചു് മോഡലിനെ പരിശീലിപ്പിക്കണം. ഇങ്ങനെ മുൻകൂട്ടി പരിശീലിപ്പിക്കപ്പെട്ടിട്ടുള്ള ഒരു വലിയ മോഡലാണു് ജിപിടി. മോഡൽ ചെയ്യുന്ന ഡാറ്റയിൽ നിന്നു് എല്ലാ രീതിയിലുള്ള സാധ്യതകളും പ്രവചിക്കാൻ ഈ മാതൃക ഉപയോഗിക്കാം. ഈ ജനറേറ്റീവ് മോഡലിൽ ഇനി വരാൻ പോകുന്ന വാക്കുകളുടെ പ്രോബബിലിറ്റി കണ്ടുപിടിക്കാനായി സെൽഫ്-അറ്റൻഷൻ മെക്കാനിസം (self-attention mechanism) എന്ന സങ്കേതവും ഉപയോഗിക്കുന്നു. ഇവയ്ക്കു് പിന്നിൽ സങ്കീർണമായ ഗണിത ശാസ്ത്രനിർദ്ധാരണങ്ങൾ ഉപയോഗിക്കപ്പെടുന്നു. ഇത്തരം മാതൃകകൾ ഭാവിയിൽ ധാരാളമായി വരുമെന്നു് കരുതപ്പെടുന്നു.
- ട്രാൻസ്ഫോമറുകൾ:
- ട്രാൻസ്ഫോർമർ എന്നതു് ഭാഷാ വിവർത്തനം, ടെക്സ്റ്റ് സൃഷ്ടിക്കൽ തുടങ്ങിയ സ്വാഭാവിക ഭാഷാ പ്രോസസ്സിംഗ് ജോലികൾക്കായി ഉപയോഗിക്കുന്ന ഒരു തരം ന്യൂറൽ നെറ്റ്വർക്ക് ആർക്കിടെക്ചറാണു്. “attention is all you need” എന്ന പേപ്പറിൽ ഗൂഗിൾ ഗവേഷകർ 2017-ൽ ഇതിന്റെ ആശയം അവതരിപ്പിച്ചു. ഒരു പ്രവചനം നടത്തുമ്പോൾ ഇൻപുട്ടിന്റെ വിവിധ ഭാഗങ്ങളുടെ പ്രാധാന്യം കണക്കാക്കാൻ മോഡലിനെ അനുവദിക്കുന്ന self-attention മെക്കാനിസങ്ങളുടെ ഉപയോഗമാണു് ട്രാൻസ്ഫോർമറിന്റെ പ്രധാന സവിശേഷത. ഇൻപുട്ട് തുടർച്ചയായി പ്രോസസ്സ് ചെയ്യുന്ന റെകരെന്റ് ന്യൂറൽ നെറ്റ്വർക്കുകളിൽ (RNN) നിന്നു് ഇതു് വ്യത്യസ്തമാണു്. ട്രാൻസ്ഫോർമർ ആർക്കിടെക്ചറിൽ ഒരു എൻകോഡറും ഡീകോഡറും അടങ്ങിയിരിക്കുന്നു. ഇവ രണ്ടും self-attention ഉള്ള ഫീഡ്ഫോർവേഡ് ന്യൂറൽ നെറ്റ്വർക്കുകളുടെ ഒന്നിലധികം പാളികൾ ചേർന്നതാണു്. എൻകോഡർ ഇൻപുട്ട് സീക്വൻസ് എടുക്കുകയും ഒരു കൂട്ടം മറഞ്ഞിരിക്കുന്ന അവസ്ഥകൾ സൃഷ്ടിക്കുകയും ചെയ്യുന്നു, അതു് ഔട്ട്പുട്ട് സീക്വൻസ് സൃഷ്ടിക്കാൻ ഡീകോഡർ ഉപയോഗിക്കുന്നു. നമ്മൾ ട്രാൻസ്ഫോമറിനു് കൊടുക്കുന്ന ഒരു വാചകം അതിനു് മറ്റൊരു ഭാഷയിലേക്ക് വിവർത്തനം ചെയ്യാനാവും. ഇതിനായി ചിത്രം ഒന്നിൽ കാണിച്ചിരിക്കുന്ന ഉദാഹരണം ശ്രദ്ധിക്കുക.

ഇതിന്റെ പ്രവർത്തനം കുറച്ചുകൂടി വിശദമായി സൂചിപ്പിക്കുന്ന ചിത്രം രണ്ടു് കാണുക.
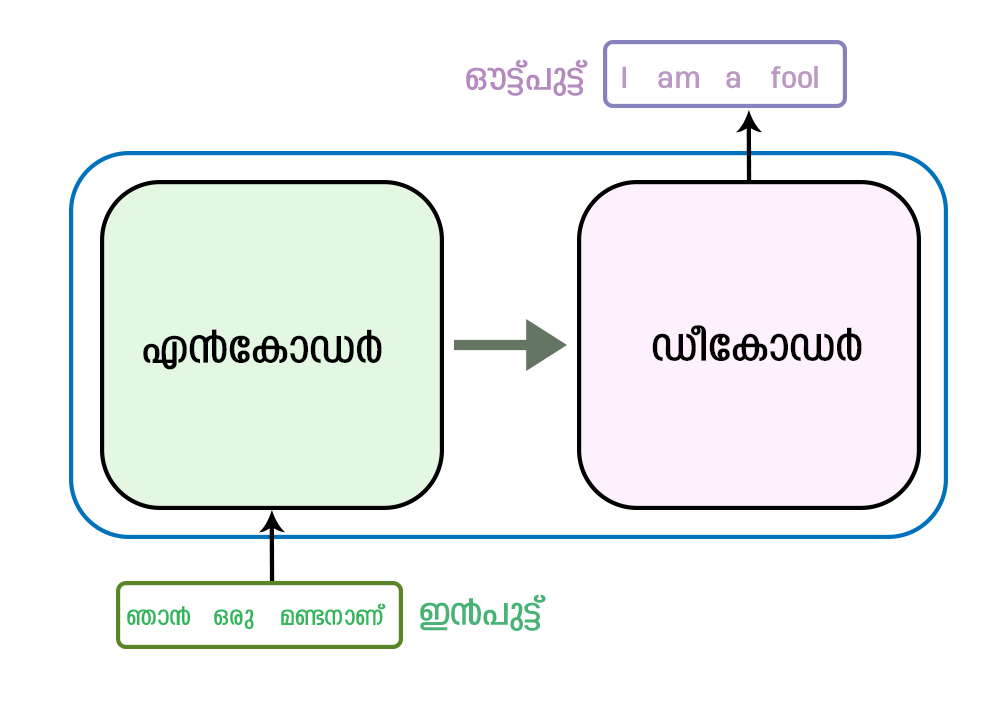
എൻകോഡർ അതിനു് ലഭിച്ച വാചകത്തിൽ നിന്നും ആശയത്തെ മനസ്സിലാക്കി ഡികോഡറുകൾക്കു് മനസ്സിലാക്കുന്ന ഫീച്ചറുകൾ ആയി ആശയത്തെ രൂപാന്തരപ്പെടുത്തി എടുക്കും. ഇങ്ങനെ രൂപാന്തരീകരണം വന്ന ആശയത്തെ മറ്റൊരു ഭാഷയിൽ പ്രകടിപ്പിക്കുക എന്നതാണു് ജോലി.
- അറ്റൻഷൻ മെക്കാനിസം:
- മനുഷ്യൻ ഭാഷ ഉഉപയോഗിച്ചാണ്പയോഗിക്കുന്നതു് വിവിധ പദങ്ങൾ ഉപയോഗിച്ചാണു്. ഭാഷയുടെ വ്യാകരണ നിയമങ്ങൾ അനുസരിച്ചു് വാക്കുകൾ ചേർത്തു് വാചകങ്ങളാക്കും. ഇങ്ങനെ ഉണ്ടാക്കുന്ന വാചകങ്ങളിൽ ആണു് ആശയങ്ങൾ അടങ്ങിയിരിക്കുന്നതു്. ഒരു വാചകത്തിലെ വിവിധ വാക്കുകൾ തമ്മിലുള്ള ബന്ധങ്ങളും ഓരോ വാക്കിനുമുള്ള പ്രാധാന്യവും കണ്ടെത്താനാണു് അറ്റൻഷൻ മോഡലുകൾ ഉപയോഗിക്കുന്നതു്.
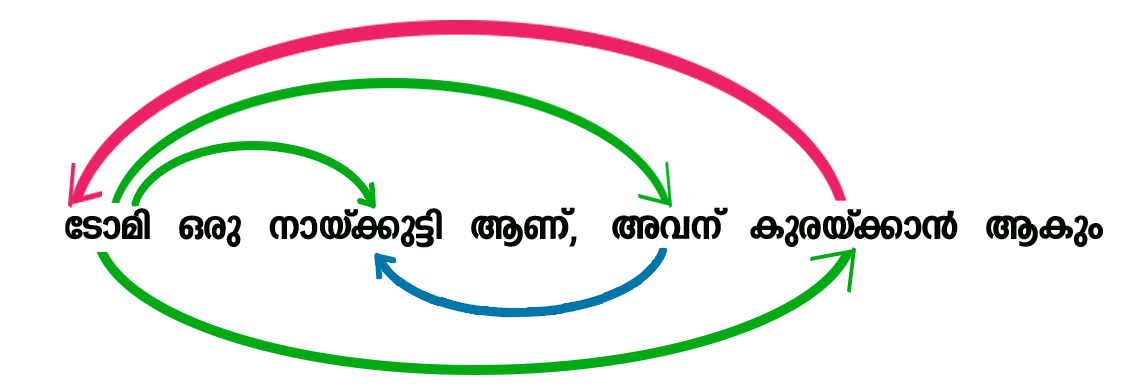
“ടോമി ഒരു നായ്ക്കുട്ടി ആണു്, അവനു് കുരയ്ക്കാൻ ആകും” എന്ന ഒരു വാചകം ഉണ്ടെന്നിരിക്കട്ടെ. ഈ വാചകത്തിലെ വാക്കുകൾ തമ്മിലുള്ള പരസ്പരബന്ധം ചിത്രത്തിൽ കാണിച്ചിരിക്കുന്നു. ഈ വാചകത്തിലെ “ടോമി” തന്നെയാണു് “അവൻ.” “ടോമി,“ “നായ്ക്കുട്ടി,” “കുരയ്ക്കാൻ, എന്നീ വാക്കുകൾ പരസ്പരം ബന്ധപ്പെട്ടിരിക്കുന്നു ഈ ബന്ധമാണു് മേൽ വാചകത്തിനു് അർത്ഥം നൽകുന്നതു്. ജിപിടി ഇത്തരം ബന്ധങ്ങളെ പരിഗണിച്ചാണു് ഭാഷയുടെ മോഡൽ നിർമ്മിച്ചിരിക്കുന്നതു്.
- പ്രീ-ട്രെയിനിംഗ്:
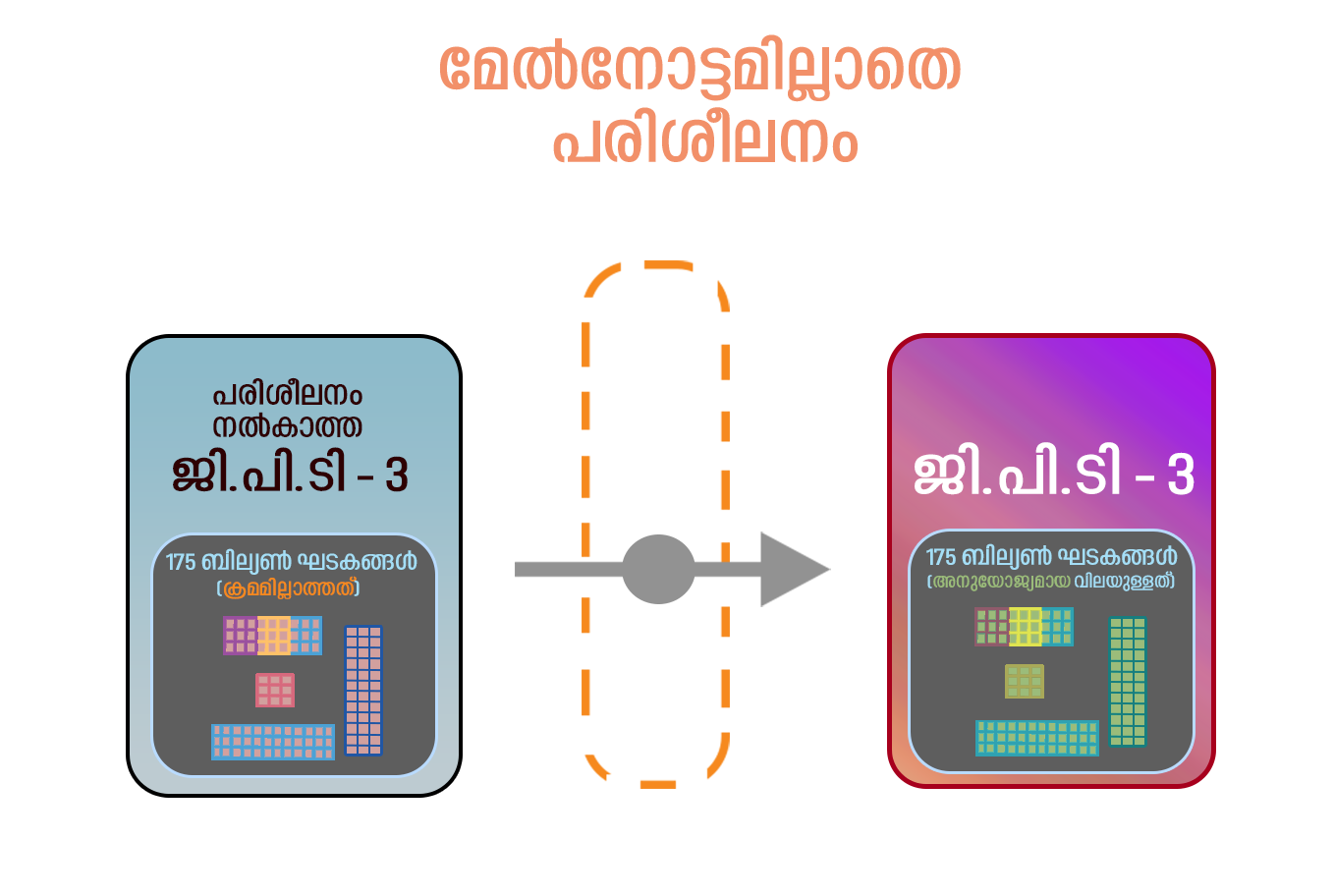
- ജിപിടിയിലെ പ്രീ-ട്രെയിനിംഗ് എന്ന പദം ഒരു വലിയ ഭാഷാ മോഡലിനെ ഒരു പ്രത്യേക പ്രവർത്തിക്കായി പരുവപ്പെടുത്തുന്നതിനു മുന്നേ ഒരു വലിയ അളവിലുള്ള ടെക്സ്റ്റ് ഡാറ്റയിൽ പരിശീലിപ്പിക്കുന്ന പ്രക്രിയയെ സൂചിപ്പിക്കുന്നു. നാച്ചുറൽ ലാംഗ്വേജ് പ്രോസസ്സിംഗ് ജോലികളുടെ പ്രാരംഭമായി ഉപയോഗിക്കാവുന്ന പൊതുവായ ഭാഷാ പ്രാതിനിധ്യങ്ങൾ (language representation) പഠിക്കുക എന്നതാണു് പ്രീ-ട്രെയിനിംഗിന്റെ ലക്ഷ്യം. പ്രീ-ട്രെയിനിംഗ് സമയത്തു്, വാക്യത്തിലെ മുൻ വാക്കുകൾ നൽകി ഒരു വാക്യത്തിലെ അടുത്ത വാക്കു് പ്രവചിക്കാൻ ജിപിടി പരിശീലിപ്പിക്കപ്പെടുന്നു. പ്രീ-ട്രെയിനിംഗ് പൂർത്തിയായിക്കഴിഞ്ഞാൽ, മറ്റു് ഡാറ്റാസെറ്റുകളിൽ പരിശീലനം നൽകി ഭാഷാ വിവർത്തനം, ചോദ്യത്തിനു് ഉത്തരം നൽകൽ, അല്ലെങ്കിൽ വാക്കുകളുടെ സംഗ്രഹം എന്നിവ പോലുള്ള നിർദ്ദിഷ്ട ജോലികൾക്കായി ഈ മോഡൽ മികച്ചതാക്കാൻ കഴിയും. ഇതിനെ ഫൈൻ ട്യൂണിംഗ് എന്നാണു് വിളിക്കുന്നതു്. മേൽനോട്ടമില്ലാത്ത (unsupervised) പ്രീ-ട്രെയിനിംഗും, സൂപ്പർവൈസ്ഡ് ഫൈൻ ട്യൂണിങ്ങും സംയോജിപ്പിക്കുന്ന ഒരു പരിശീലന മാതൃകയാണു് ജിപിടിയിൽ ഉപയോഗിക്കുന്നതു്. ഈ മാതൃക രണ്ടു് പ്രശ്നങ്ങൾ പരിഹരിക്കുന്നു: ഒന്നാമതു് ചെലവേറിയ ലേബൽ ചെയ്ത ഡേറ്റ ആവശ്യമില്ല, രണ്ടാമതു് വലിയ ഡേറ്റാസെറ്റുകളില്ലാതെ തന്നെ പ്രവർത്തികൾ ചെയ്യാൻ കഴിയും. ചുവടെയുള്ള ചിത്രം കാണുക:
- ഡേറ്റാസെറ്റ്:
-
GPT-3-യിൽ ഏതാണ്ടു് 30,000 കോടി വാക്കുകൾ (ടോക്കണുകൾ) ഉപയോഗിച്ചു് പരിശീലനം നൽകിയിരിക്കുന്നു. നമ്മൾ നൽകുന്ന വാക്കുകളിൽ നിന്നും നമ്മളുമായി സംവദിക്കാൻ ആവശ്യമായ വാക്കുകൾ പ്രവചിക്കുക എന്ന പ്രവർത്തിക്കുള്ള പരിശീലനമാണു് ഇതിനു് നൽകിയിട്ടുള്ളതു്. ഉദാഹരണത്തിനു്:
- നമ്മൾ:
- “സാധനം കയ്യിൽ?”
- ജിപിടി:
- “സാധനം കയ്യിൽ ഉണ്ടോ?”
ഒരു ആശയം നൽകിയാൽ അതിനു യോജിച്ച വെബ്സൈറ്റ് ഉണ്ടാക്കാനുള്ള കോഡ് സൃഷ്ടിക്കുക, സ്പ്രെഡ്ഷീറ്റുകളിൽ പ്രവർത്തിച്ച് പ്രവചനങ്ങൾ നടത്തുക, നമുക്കാവശ്യമുള്ള ഒരു വിവരം ക്രോഡീകരിച്ചു് നൽകുക, വിവിധ ഭാഷകളിലേക്കു് തർജ്ജമ നടത്തുക, ഇത്യാദിയെല്ലാം ചെയ്യുന്ന ഒരു ട്രാൻസ്ഫോമർ മാതൃകയിൽ പ്രവർത്തിക്കുന്ന ചാറ്റ്ബോട്ടാണു് ഇതു്. പരസ്പരബന്ധമില്ലാത്ത മറുപടികൾ ചിലപ്പോൾ തരുമെങ്കിലും ചാറ്റ്ജിപിടിയുടെ കഴിവിനെ അക്കാദമിക സമൂഹം കരുതലോടെയാണു് സമീപിക്കുന്നതു്. ഇന്റർനെറ്റിൽ ലഭ്യമായ എല്ലാ അറിവുകളും, ആശയവിനിമയങ്ങളും നൽകി പരിശീലിപ്പിച്ചിരിക്കുന്ന ഈ സങ്കേതത്തിനു് മനുഷ്യനേക്കാൾ മെച്ചമായ കൃതികൾ സൃഷ്ടിക്കാനാവുന്നതിൽ അത്ഭുതമില്ല. ഒരു കോളേജ് വിദ്യാർത്ഥിയെക്കാൾ മെച്ചമായി ഇതിനു് എഴുതാനാവും. കലാസാഹിത്യ ലോകം മാത്രമേ പേടിക്കേണ്ടതുള്ളൂ എന്നു് കരുതാൻ വരട്ടെ. ഒരു ശരാശരി കമ്പ്യൂട്ടർ പ്രോഗ്രാമറെക്കാൾ നന്നായി പ്രോഗ്രാമുകൾ എഴുതാനും അതിനു് സാധിക്കും. ഉദാഹരണത്തിനു് ഒരു സംഖ്യയുടെ ഫാക്ടോറിയൽ കണ്ടു് പിടിക്കാനുള്ള പൈതൺ പ്രോഗ്രാം എഴുതാമോ എന്ന ചോദ്യത്തിനു് ആ പ്രോഗ്രാം മാത്രമല്ല, അതിന്റെ അൽഗോരിതം, അതുപയോഗിച്ചുള്ള ഒരു ഉപയോഗം എന്നിവ സോദാഹരണ സഹിതം നൽകാൻ ചാറ്റ്ജിപിടിയ്ക്ക് ഇരുപതു് സെക്കന്റുകളേ വേണ്ടി വന്നുള്ളൂ.
ഇംഗ്ലീഷിൽ നടത്തുന്ന സംഭാഷണങ്ങൾക്കു് വളരെ വേഗത്തിലും കൃത്യവുമായ പ്രതികരണങ്ങൾ ചാറ്റ്ജിപിടി നൽകുന്നുണ്ടെങ്കിലും മലയാളം പോലുള്ള ഭാഷകളിൽ ഉള്ളവ അല്പം സാവധാനത്തിൽ ആണെന്നു് മാത്രമല്ല പ്രത്യേകിച്ചു് യാതൊരു അർത്ഥവുമില്ലാത്തവയുമാണു്. ലേഖനങ്ങൾക്കു് വലിയ തെറ്റു് പറയാൻ പറ്റില്ലെങ്കിലും മലയാളത്തിൽ എഴുതുന്ന കവിതയൊക്കെ ശുദ്ധ അബദ്ധമാണു്. ഒരു മൂന്നാം തലമുറ ചാറ്റ് എഞ്ചിനായ ജിപിടി-3 ഏകദേശം 17500 കോടി ഘടകങ്ങൾ ഉപയോഗിച്ചു് പരിശീലനം നല്കപ്പെട്ടതാണു്. വിവിധ ഭാഷകളിലേക്കു് വിവർത്തനങ്ങൾ അനായാസം ചെയ്യാൻ കഴിയുന്ന ഇതിനു്, വാക്യഘടന മനസ്സിലാക്കുക, ജീവചരിത്രപരമായ ഉപന്യാസങ്ങളും കാല്പനിക കവിതകളും രാഷ്ട്രീയ വിമർശനങ്ങളും എഴുതുക, ഗണിത സമവാക്യങ്ങൾ ക്രിയാത്മകമായി പരിഹരിക്കുക എന്നീ ക്രിയകളും ചെയ്യാൻ കഴിയും. കുമാരനാശാന്റെ കവികളെക്കുറിച്ചു് ഏതാനും വാചകങ്ങൾ എഴുതാൻ ആവശ്യപ്പെട്ടപ്പോൾ താഴെക്കൊടുത്ത പ്രതികരണം ലഭിക്കാൻ പത്തു് നിമിഷങ്ങളേ വേണ്ടിവന്നുള്ളൂ (ചാറ്റ്ജിപിടിയുടെ തർജ്ജമ മോശമായതിനാലും, അതു് മലയാളത്തിൽ നൽകുന്ന വാക്യങ്ങളുടെ വ്യാകരണം ശരിയല്ലാത്തതിനാലും ഇംഗ്ലീഷിൽ സൃഷ്ടിച്ചു് ഗൂഗിൾ തർജ്ജമ ചെയ്തതു്):
“കുമാരനാശാൻ (ആശാൻ എന്നും അറിയപ്പെടുന്നു) ഇന്ത്യയിലെ പ്രശസ്തനായ കവിയും തത്ത്വചിന്തകനുമായിരുന്നു. വള്ളത്തോൾ നാരായണ മേനോൻ, ഉള്ളൂർ എസ്. പരമേശ്വര അയ്യർ എന്നിവരോടൊപ്പം ആധുനിക മലയാള സാഹിത്യത്തിലെ ത്രിമൂർത്തികളിലൊരാളായി അദ്ദേഹം കണക്കാക്കപ്പെടുന്നു. കുമാരനാശാന്റെ കവിതകൾ പ്രണയം, പ്രകൃതി, ആത്മീയ വിമോചനം എന്നിവയുടെ പ്രമേയങ്ങൾ പര്യവേക്ഷണം ചെയ്യുന്നു. ”വീണ പൂവ്”, ”ആ ദിവ്യ ചരിത്രം”, ”കരുണ”, ”ആത്മോപദേശ ശതകം” എന്നിവ അദ്ദേഹത്തിന്റെ പ്രശസ്തമായ കവിതകളിൽ ചിലതാണു്. ഭഗവദ് ഗീത മലയാളത്തിലേക്ക് വിവർത്തനം ചെയ്തതിലും അദ്ദേഹം പ്രശസ്തനാണു്.”
മേൽപ്പറഞ്ഞ കാര്യം എല്ലാം സത്യമാണോ എന്നതു് ആ വിഷയത്തിൽ അറിവുള്ള ഒരാൾക്കേ മനസ്സിലാക്കാനാവൂ എങ്കിലും ഈ പ്രതികരണം അവിശ്വസനീയമാണു്. ഇത്തരം കാര്യങ്ങളിൽ പ്രതികരണം വലിയ മോശമല്ലെങ്കിലും വിവിധ ഭാഷകളിലുള്ള സാഹിത്യ കൃതികളൊക്കെ സൃഷ്ടിക്കാൻ ഇതിനു് ഇനിയും കഴിവു് വേണ്ടവിധം ആർജ്ജിക്കാനായിട്ടില്ല. 2022 ആദ്യത്തോടെ പരിശീലനം പൂർത്തിയായ ചാറ്റ്ജിപിടി-3നു പകരം 2023 ആദ്യം പുറത്തിറങ്ങുന്ന ചാറ്റ്ജിപിടി-4 ഇത്തരം പോരായ്മകൾ മറികടന്നേക്കാം.
ഒരു ലക്ഷം കോടി ഘടകങ്ങൾ (1 trillion parameters) ഉപയോഗിച്ചു് പരിശീലനം നൽകിക്കൊണ്ടിരിക്കുന്ന GPT-4നു് ഒരു മനുഷ്യ മസ്തിഷ്ക്കത്തിനു് സമാനമായ ചിന്താശേഷി ഉണ്ടാവും. കമ്പ്യൂട്ടർ ഹാർഡ്വെയർ മേഖലയിലുണ്ടായ വളർച്ചയാണു് ഇതിനു പിന്നിൽ. മനുഷ്യ മസ്തിഷ്ക്കത്തിൽ ശരാശരി 8600 കോടി ന്യൂറോണുകൾ ഉള്ളപ്പോൾ ജിപിടി-4നു് ഒരു ലക്ഷം കോടി ന്യൂറൽ നെറ്റ്വർക്കുകൾ ലഭ്യമാണു്. നിലവിൽ വാക്കുകൾ ടൈപ്പ് ചെയ്തു് കൊടുക്കുന്ന അവസ്ഥയ്ക്കു് പകരം ഓഡിയോ, വീഡിയോ ഇൻപുട്ടുകൾ സ്വീകരിക്കാൻ ചാറ്റ്ജിപിടി-4ക്കു് കഴിയും. മൾട്ടിമോഡൽ ഇൻപുട്ട്-ഔട്ട്പുട്ട് മോഡൽ എന്നറിയപ്പെടുന്ന ഇതിനു് മുൻപേയുള്ള മോഡലുകളെക്കാൾ പരിശീലന ചെലവു് കുറവുമാണു്. കോപ്പിയെഴുത്തു്, കസ്റ്റമർ സപ്പോർട്ട്, കമ്പ്യൂട്ടർ പ്രോഗ്രാമിംഗ് തുടങ്ങിയ മേഖലകളിൽ ഇതു് മനുഷ്യരുടെ ജോലി ഇല്ലാതാക്കിയേക്കാം. ഭാവിയിൽ ഒരു പിഎച്ച്ഡി പ്രബന്ധമൊക്കെ എളുപ്പത്തിൽ എഴുതിയുണ്ടാക്കാൻ ഇതിനു അനായാസം സാധിച്ചേക്കാം എന്നു് കരുതപ്പെടുന്നു.
നിലവിൽ ചാറ്റ്ജിപിടി-3 ഉപയോഗിച്ച് നടത്തിയ ഒരു പരീക്ഷണത്തിൽ ഒരു ശാസ്ത്ര വിഷയത്തിൽ സൂചികകൾ സഹിതം ഒരു ലേഖനം എഴുതാൻ അതിനു സാധിച്ചെങ്കിലും എല്ലാ സൂചികകളും കൃത്യമായിരുന്നില്ല. പക്ഷെ ഈ ലേഖനം കോപ്പിയടി ടെസ്റ്റിനു വിധേയമാക്കിയപ്പോൾ ഒരു വിധ കോപ്പിയടിയും ഇല്ലാ എന്നാണു് സോഫ്ട്വെയർ കാണിച്ചതു്. ഇതു് മനുഷ്യർ എഴുതുന്ന ലേഖനങ്ങളിൽ വരികയെന്നതു് വളരെ വിഷമം പിടിച്ച കാര്യമാണു്. എന്നാൽ ഇത്തരം സാങ്കേതിവിദ്യ വിദ്യാർത്ഥികൾ സ്വപ്രയത്നമില്ലാതെ സൃഷ്ടികൾ നടത്തി കബളിപ്പിക്കുമെന്ന ആശങ്ക അസ്ഥാനത്താണു്. കാരണം, അതു് കണ്ടു് പിടിക്കുന്ന സോഫ്റ്റ്വെയർ ഇറങ്ങിക്കഴിഞ്ഞു. എന്നിരുന്നാലും നമ്മുടെ വിദ്യാഭ്യാസ സമ്പ്രദായത്തിന്റെ ഘടന മാറ്റിമറിച്ചേക്കാവുന്ന ഒരു കണ്ടുപിടിത്തമാണിതെന്നതിൽ സംശയം വേണ്ട. വിദ്യാർത്ഥികളെ സംബന്ധിച്ചിടത്തോളം ഇന്റർനെറ്റിൽ തെരയലും, തർജ്ജമയ്ക്കുമൊക്കെ അപ്പുറം അവർക്ക് പഠിക്കേണ്ട വിഷയങ്ങളെപ്പറ്റി ചർച്ച നടത്താനും ആവശ്യമായ ഉത്തരങ്ങൾ നൽകാനും ഉള്ള ഒരു സഹായിയായി മാറാൻ ചാറ്റ്ജിപിടിയ്ക്കു് കഴിയുമെന്നതു് ഒരു വലിയ മാറ്റമാണു്. നിരവധി ലിങ്കുകൾ പരതി സമയം മെനക്കെടുത്താതെ കൃത്യമായ ഉത്തരങ്ങൾ നിമിഷങ്ങൾക്കുള്ളിൽ നല്കുമെന്നതു് വളരെ സൗകര്യപ്രദമായ കാര്യമാണു്.
ഇതൊക്കെയാണെങ്കിലും ഇത്തരം സാങ്കേതികവിദ്യയിൽ ഇപ്പോഴും മുന്നിൽ നിൽക്കുന്നതു് ഗൂഗിളാണു്. പാം (PaLM–പാത്വെയ്സ് ലാംഗ്വേജ് മോഡൽ) എന്ന ന്യൂറൽ നെറ്റ്വർക്ക് അധിഷ്ഠിത മാതൃക 54,000 കോടി ഘടകങ്ങൾ ഉപയോഗിക്കുന്നതും ഈ മേഖലയിൽ ഏറ്റവും മുന്നിൽ നിൽക്കുന്നതുമാണു്. ഗൂഗിൾ, മെറ്റാ, ആപ്പിൾ തുടങ്ങിയ കമ്പനികൾ ചാറ്റ്ജിപിടിയെ വെല്ലുന്ന സാങ്കേതികവിദ്യ സൃഷ്ടിക്കാനുള്ള പണിപ്പുരയിലാണു്. ആൻഡ്രോയ്ഡ് ഉപകരണങ്ങളിലുള്ള ഗൂഗിൾ അസിസ്റ്റന്റ്, ഗൂഗിൾ ട്രാൻസ്ലേറ്റ്, അതുപോലെ ഗൂഗിൾ ക്ളൗഡിൽ പ്രവർത്തിക്കുന്ന ഡോക്സ്, ഷീറ്റ് തുടങ്ങിയ ആപ്പുകളൊക്കെ നിർമിതബുദ്ധി സേവനങ്ങൾ നൽകുന്നവയാണു്. ബെർട്ട് (BERT–Bidirectional Encoder Representations from Transformers) എന്ന മോഡൽ കാലങ്ങളായി അവരുടെ സെർച്ചിനെ സഹായിക്കുന്നുണ്ടു്. ഗൂഗിൾ ചാറ്റിൽ ഉപയോഗിക്കുന്ന ലാംഡ (LaMDA) ചാറ്റ്ബോട്ടും നിർമിതബുദ്ധി അധിഷ്ടിതമാണു്.
പൊതുവേ, GPT-4 പോലെയുള്ള ഭാഷാ മോഡലുകൾക്കു് മനുഷ്യനെപ്പോലെ വാക്കുകൾ സൃഷ്ടിക്കാനും മനുഷ്യന്റേതിൽ നിന്നു് വേർതിരിച്ചറിയാൻ പ്രയാസമുള്ള സംഭാഷണങ്ങൾ തുടരാനും കഴിയും. എന്നിരുന്നാലും, ഒരു മനുഷ്യനെപ്പോലെ അവരുടെ പ്രതികരണങ്ങളുടെ ഉള്ളടക്കം മനസ്സിലാക്കാനോ ന്യായവാദം ചെയ്യാനോ ഉള്ള കഴിവു് നിലവിൽ അവയ്ക്കില്ല. അതിവേഗം പുരോഗമിച്ചു കൊണ്ടിരിക്കുന്ന നിർമ്മിത ബുദ്ധി ഗവേഷണങ്ങളുടെ ഭാവി പ്രവചിക്കുക എന്നതു് അത്ര എളുപ്പമല്ല. അതോടൊപ്പം ഓരോ ദിവസവും പുതിയ പുതിയ ഉപയോഗങ്ങൾ കണ്ടെത്തിക്കൊണ്ടു് ഇരിക്കുന്നതിനാൽ വരും കാലം ആവേശകരമായിരിക്കുമെന്നു് തീർച്ച.
- https://papers.neurips.cc/paper/7181-attention-is-allyou-need.pdf
- https://jalammar.github.io/illustrated-transformer/
- റെഡ്ഡിറ്റിന്റെ ഓപ്പൺ എ ഐ ത്രെഡിൽ നിന്നുള്ള പോസ്റ്റുകൾ https://www.reddit.com/r/OpenAI/
- https://openai.com/blog/chatgpt/

Associate Professor of Physics, Govt. College, Kassargod, Senior Member of ieee and ted Fellow.
Masters in Physics and Ph. D. from cusat. Computational Physicist by training and current interests are Data Science, and Science Communication.
Email: paul.jijo@gmail.com

Principal, College of Engineering, Attingal.
Masters in Computer Science from Cochin University of Science and Technology, Ph. D. from Department of Electrical Engineering from Indian Institute of Technology, Bombay. Present interests are in machine learning, artificial intelligence, communication systems and free software.
Email: vu2swx@gmail.com